5. Distributed Databases
5.1 Introducción
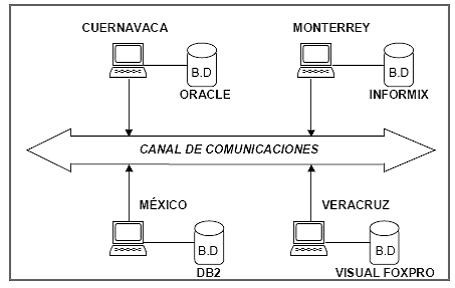
Un sistema de bases de datos distribuidas se compone de un conjunto de sitios conectados entre sí mediante algún tipo de red de comunicaciones en el cual:
- Cada sitio es un sistema de B.D. por sí mismo.
- Los sitios han convenido en trabajar juntos con el fin de que un usuario de cualquier sitio pueda obtener acceso a los datos de cualquier punto de la red tal como si todos los datos estuvieran almacenados en el sitio propio del usuario.
 |
5.2 Definición
Base de Datos Distribuida
- DDBMS (Distributed DBMS). Es el software que administra todas las bases de datos de los sitios y proporciona un mecanismo de acceso que hace
transparente esta distribución a los usuarios. - Esta regla conduce a 12 objetivos o reglas secundarias:
- Autonomia local.
- No dependencia de ningun sitio central.
- Operación continua.
- Independencia con respectos a la localización (transparencia de localización).
- Indepencia con respecto a la fragmentación.
- Independencia de réplica.
- Optimización en el procesamiento distribuido de consultas.
- Manejo de transacciones distribuídas
- Independencia con respecto al equipo.
- Independencia con respecto al sistema operativo.
- Independencia con respecto a la red.
- Independencia con respecto al DBMS.
Ventajas de los DDBMS
- Autonomia local.
- Mejora la confiabilidad / disponibilidad.
- Mejora de la eficiciencia.
- Expandibilidad.
- Economía en cuanto crecimiento incremental.
- Compartición de recursos.
Areas problemas de los DDBMS
- Diseño de base de datos distribuídas.
- Procesamiento de querys distribuídos.
- Administración del diccionario de datos.
- Control de concurrencia distribuído.
- Administración del deadlock distribuído.
- Recuperación de transacciones en ambientes distribuídos.
- Base de datos heterogeneas (Multibase de datos).
- Relación cruzada entre los problemas anteriores.

5.3 Fragmentación
5.3.1 Definición
Fragmentación es la descomposición o partición de una tabla en pedazos llamados fragmentos.
La fragmentación básicamente se puede hacer de dos formas:
- Fragmentación Horizontal. selecciona registros completos de una relación
- Fragmentación Vertical. selecciona
columnas completas de una relación
5.3.2 Reglas a Cumplir por Fragmentación
- Condición de Completés.
Todos los datos de la relación global deberán ser mapeados a algún fragmento. - Condición de Reconstrucción.
Deberá ser siempre posible reconstruir la relación global a partir de sus fragmentos. - Condición de Conjuntos Disjuntos.
Es conveniente que los fragmentos sean disjuntos.
5.3.3 Fragmentación Horizontal
Definir fragmentos horizontales se hace a
través del operador de selección del algebra relacional operando sobre una relación global.
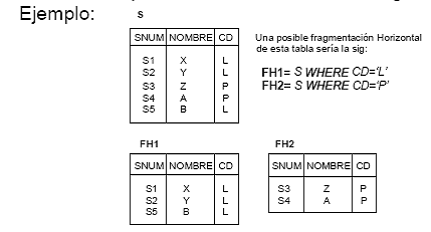 |
Los predicados que nos permiten definir una
fragmentación de una relación son llamados la calificación de la fragmentación.
En el ejemplo
la calificación de la fragmetación hecha a S, son:
q1 : CD = ‘L’
q2 : CD = ‘P’
En general una fragmentación horizontal es
correcta, si cumple que:
- El conjunto de calificaciones mapea todo el dominio del atributo(s) bajo el cual se hace la calificación.
- Si siempre es posible reconstruir la tabla
global por medio del operador UNION del
algebra relaciónal:
R = F1 UNION F2 UNION …UNION Fn - Si todas las calificaciones de los fragmentos
son mutuamente exclusivas, es decir, si al
aplicar las calificaciones se producen fragmentos que al intersectarlos generan un
conjunto vacio.
F = F1 INTERSECT F2 INTERSECT ..
INTESECT Fn
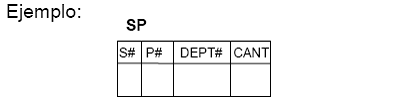
5.3.4 Fragmentación Horizontal Derivada
Este tipo de fragmentación particiona una tabla en base a un atributo(s) que esta presente en otra tabla(s).
 |
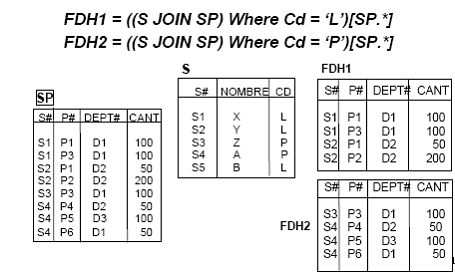
Los fragmentos se definirían de la sig. manera:
 |
5.3.5 Fragmentación Vertical
Definir fragmentos verticales se hace a través
del operador de proyección del algebra relacional operando sobre una relación global.
 |
Una característica importante de la
fragmentación vertical, es que todos los fragmentos deben incluir la llave primaria de la
relación global.
La razón es que si no incluímos la llave primaria
no es posible reconstruir la relación original.
Para reconstruir la relación original debemos
realizar un JOIN de todos los fragmentos.
R = F1 JOIN F2 JOIN … JOIN F3
En fragmentación vertical no se cumple que los
fragmentos sean disjuntos (la llave está repetida
en todos los fragmentos).
5.3.4 Fragmentación Híbrida
Consiste en aplicar las operaciones de fragmentación vistas anteriormente de manera recursiva, satisfaciendo las
condiciones de correctés cada vez que se
realiza la fragmentación.
La reconstrucción puede ser obtenida
aplicando las reglas de reconstrucción en
orden inverso.
De esta forma podemos fragmentar nuestra
tabla global en los pedazos que queramos y
como queramos.
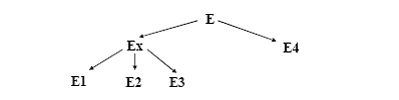
Ejemplo: Considere la relación de empleado (E).
Una posible fragmentación híbrida sería:
E1 = Ex[Emp#, Nombre, #Jefe,Dept#] Where Dept# <10 |
5.4 Transacciones distribuidas
5.4.1 Definición
- Una transacción distribuida es aquella que involucra algún proceso en distintos sitios de la red. Llamaremos a estos procesos los agentes de la transacción, entonces una transacción distribuida esta compuesta por varios agentes.
- Para llevar a cabo una transacción
distribuida los agentes tienen que
comunicarse a través de mensajes en la
red y se debe garantizar la atomicidad
de la transacción.
Requiere:
- Existe un agente raíz que inicia toda la transacción, así que cuando el usuario requiere la ejecución de una aplicación distribuida el agente raíz es iniciado; el sitio del agente raíz es llamado el sitio origen de la transacción.
- El agente raíz tiene la responsabilidad
de asegurar BEGIN-TRANSACTION,
COMMIT O ROLLBACK de toda la
transacción distribuida.
5.4.2 Recuperación de transacciones distribuidas
- Para realizar la recuperación de transacción distribuidas se asume que cada sitio tiene su propio manejador de transacción local (LTM).
- Cada agente utiliza de manera local las
primitivas asociadas a sus transacciones.
Podemos llamar a los agentes
subtransacciones, lo cual origina distinguir las
primitivas BEGIN-TRANSACTION, COMMIT Y
ROLLBACK asociado a la transacción
distribuida de la primitivas locales utilizada por
cada agente en LTM; para poder distinguir una de las otras, a las ultimas les llamaremos:
LOCAL-BEGIN, LOCAL-COMMIT Y LOCALROLLBACK. - Para propósito del manejador de transacciones
distribuidas (DTM), requieren que los LTM se
conformen de la siguiente manera:
- Asegurar la atomicidad de su transacción.
- Grabar en bitácora por ordenes de la
transacción distribuida.
Para asegurar que todas las acciones de una transacción distribuida son ejecutadas o no ejecutadas dos condiciones son necesarias:- En cada sitio todas las acciones son ejecutadas o ninguna es ejecutada.
- Todos los sitios deberán tomar la misma decisión respecto al COMMIT o ROLLBACK de la transición global.
5.4.3 Commit de 2 fases
En este protocolo hay un agente que tiene un papel especial, este agente es llamado el coordinador (el cual es el agente raíz) y todo los demás agentes son llamados PARTICIPANTES.
El COORDINADOR es el responsable de tomar la decisión de hacer un COMMIT o un ROLLBACK GLOBAL y cada PARTICIPANTE es responsable de grabar a sus bitácoras y bases de datos locales.
La idea básica del protocolo en dos fases
(2pl, 2 phase locking) es determinar una decisión única para
todos los participantes con respecto a hacer
un COMMIT o un ROLLBACK en todas las
subtransacciones locales.
La primera fase de este protocolo tiene como objetivo lograr una decisión común, la meta de la segunda fase es llevar a cabo esta decisión.
En términos generales el commit de 2 fases en bases de datos distribuidas funciona muy similar a commit de 2 fases tradicional.
"En toda transacción, todos los locks preceden a todos los unlocks".