8. Datos no estructurados
8.1 Introducción
Colecciones no estructuradas
• Datos sin tipos pre-definidos
• Se almacenan como “documentos” u “objetos” sin estructura uniforme
• Se recuperan con apoyo de índices y modelos de “RI” para determinar su relevancia respecto a consultas del usuario
• Ejemplos:
- Correspondencia, diarios, novelas, blogs
Recuperación de Información (RI)
• Area de las ciencias computacionales que estudia técnicas y métodos para indexar y consultar colecciones de diversos niveles de estructura
• Proceso para determinar los documentos relevantes para un tema especificado por el usuario
– Ejemplo:
“Encontrar documentos sobre historia de los juegos olímpicos”
– El problema involucra interpretar, comparar, jerarquizar,…
• Comparar con recuperación de datos:
– Obtención de todos los elementos en una colección que satisfacen totalmente condiciones claramente especificadas.
Ejemplo: Encontrar los nombres de todos los estudiantes de la
carrera de ISC
– El problema es sencillo si se cuenta con una base de datos relacional:
• select nombre from estudiantes where carrera = ‘IS’
RI cobra importancia
• Se inicia con tablas de contenido e índices de libros
• Las bibliotecas introdujeron índices a múltiples publicaciones, referencias cruzadas e índices jerárquicos para clasificar documentos
• Desde los 40s, se inicia RI orientado a indexar y recuperar textos pero la recuperación de datos domina
• En los 90s, el desarrollo de WWW hace de RI un área fundamental y acelera su evolución
• RI incluye ahora modelado, indexado, clasificación, interfaces de usuario, visualización de datos textuales, multimediales e hipertextuales
• Meta: Dada una consulta, obtener todos los documentos relevantes posibles y minimizar el número de documentos irrelevantes
El reto
• El enfoque inicial: clasificar documentos
• El problema: quien categoriza no coloca los documentos donde espera encontrarlos quien busca, a veces ni el mismo clasificador (ej. archivos personales, folders de correo electrónico)
• Otro enfoque: “entender” el contenido y responder a consultas
• Problema: El procesamiento de lenguaje natural aún no es lo suficientemente general (¿ni lo será?)
• La alternativa: RI, basada en reconocimiento de patrones, muestreo estadístico, aprendizaje maquinal, probabilidad,…
• La meta de RI: encontrar documentos relevantes rápidamente
• RI será un área de investigación mientras los métodos existentes no sean suficientemente efectivos y eficientes simultáneamente
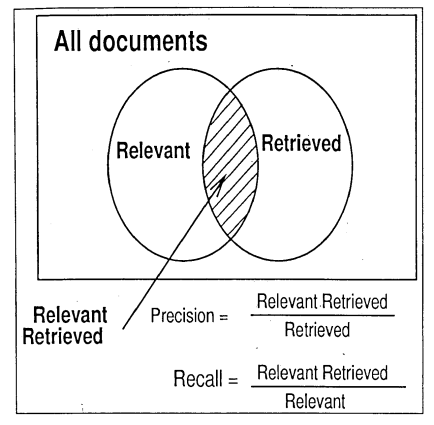
Medidas de efectividad de RI
• Precisión (o “especificidad”)
• Cobertura (o “exhaustividad”)


Visión Lógica de los Documentos
Es la representación de documentos y/o páginas web que forman parte de una colección (sistema de IR).

La forma más común de representar un documento de texto es por un sistema de términos indexados o palabras llaves.
Estos términos son extraídos con el siguiente proceso:
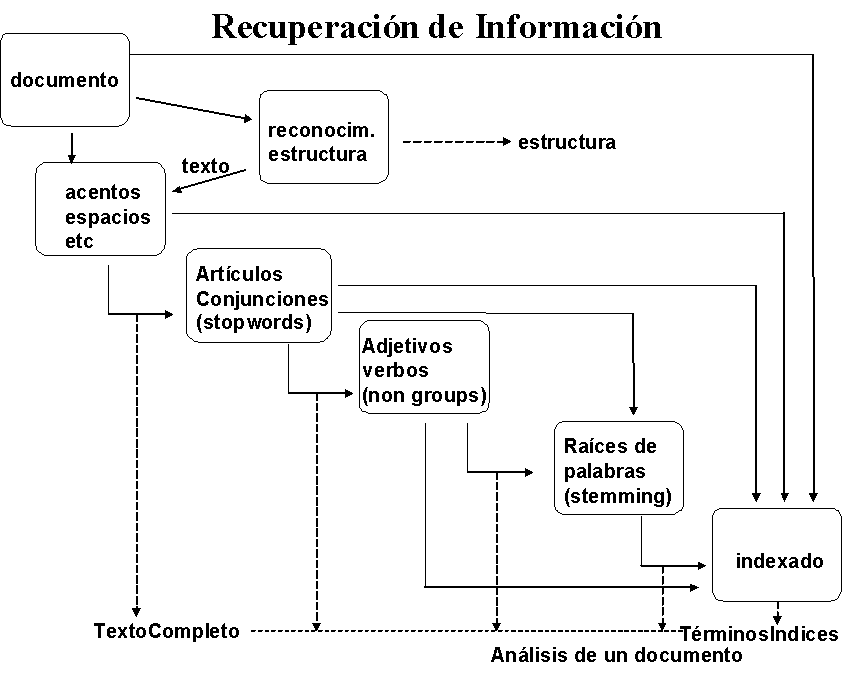
Para la lematización los "stopwords" generalmente se utilizan listas de palabras, ya sean de un lenguaje controlado (alguna especialidad) o bien de un idioma particular.
Por otro lado para realizar el “stemming” (reducir palabras de su raíz gramatical) se emplea el algoritmo de Porter, solo que hay que tener en cuenta el idioma a utilizar ya que por lo general se encuentra en inglés aunque hay versiones para español.
http://www.tartarus.org/~martin/PorterStemmer/
Existen 2 tipos de tareas principales en la recuperación de información:
-
Las centradas en la computadora: consiste en construir un índice eficiente, procesar las consultas del usuario con un alto rendimiento y algoritmos (modelos de recuperación) que mejoren la calidad de respuesta del sistema.
-
Las centradas en el humano: consiste principalmente en estudiar las necesidades del usuario, saber cómo afecta a la organización, operación y visualización de resultados en el sistema de recuperación.
8.2 Modelos de Recuperación
Modelos clásicos de RI
• Booleano, vectorial y probabilístico
• Diseñados para colecciones de texto
• El modelo lógico de los documentos consiste de “términos” o palabras que se refieren (indexan) al tema principal tratado
• Algunas propiedades útiles:
- Los términos que aparecen en casi todos los documentos no son útiles
- Algunos términos pueden tener mayor relevancia con respecto a un documento dado, lo que se puede denotar por un “peso” del término
- Para un término ki y un documento dj, wi,j >=0 denota la importancia del término para describir el contenido del documento
- Para una colección con t términos, puede definirse el vector Dj = (w1,j, w2,j,… wt,j)
8.2.1 Clasificación

8.2.2 Modelo Booleano
El modelo Boleano, es un modelo de recuperación simple basado en la teoría fija y álgebra de Boolean, este modelo proporciona un grupo de trabajo que es fácil de usar por un usuario común de un sistema de IR. Además, las llamadas se especifican como expresiones de Boolean que tienen la semántica precisa.
Dado su simplicidad inherente y formalismo, el modelo de Boolean recibió la gran atención y se adoptó por muchos de los sistemas bibliográficos comerciales.
De este modelo se pueden destacar los siguientes puntos:
-
La relevancia es binaria: un documento es relevante o no lo es.
-
Consultas de una palabra: un documento es relevante si contiene la palabra.
-
Consultas AND: Los documentos deben contener todas las palabras.
-
Consultas OR: Los documentos deben contener alguna palabra.
-
Consultas A BUTNOT B: Los documentos los documentos deben ser relevantes para A pero no para B.
· Ejemplo: lo mejor de Maradona
Maradona AND Mundial
AND (( México ’86 OR Italia ’90) BUTNOT U.S.A. ’94) -
Es el modelo mas primitivo, sin embargo es el mas popular.
¿Por qué es malo?
-
No discrimina entre documentos más y menos relevantes.
-
Da lo mismo que un documento contenga una o cien veces las palabras de consulta.
-
Da lo mismo que cumpla una o todas las cláusulas de un OR.
-
No permite ordenar los resultados.
-
Puede resultar confuso
Ejemplo: Necesito investigar sobre los Aztecas y los Incas
Aztecas AND Incas
(cuando en realidad lo que se pretendía era: Aztecas OR Incas).
¿Por qué es popular?
-
Es una de los primeros modelos que se implemento y muchos de los primeros sistemas de IR se basaron en él
-
La idea suele ser común entre los usuarios que la están usando.
-
Es la opción favorita para insertar texto en un RDBMS.
-
Es simple de formalizar y eficiente de implementar.
-
En algunos caso (usuarios expertos) puede ser adecuado.
-
Puede ser útil en combinación con otro modelo ej. Para excluir documentos.
-
Puede ser útil con buenas interfaces.
Tablas posibles para el modelo booleano
• Docs (IdDoc, NombreDoc, FechaPub, …, texto)
• IndiceInv (IdDoc, Term)
• Consulta (Term)
• Un pre-proceso puede producir Docs (extrayendo datos de archivos) e
IndiceInv (vía parser, lematización, eliminación de palabras vacías)
Uso de SQL para el modelo booleano
• Encontrar los ids de documentos que contengan los término “casa” o “blanca”
– select distinct IdDoc from IndiceInv
where term = ‘casa’ or term = ‘blanca’
• Recuperar el texto de los documentos…
– select texto from Docs
where IdDoc in
(select distinct IdDoc from IndiceInv
where term = ‘casa’ or term = ‘blanca’)
• ¿Cómo se obtendrían los documentos que contienen “casa” y “blanca”?
SQL para el modelo booleano
• “AND” usando agregación y agrupación:
– select IdDoc from IndiceInv i, Consulta q
where i.term = q.term
group by i.IdDoc
having count(i.term) = (select count(*) from Consulta)
• en este caso, “where” asegura que se incluyen los términos pedidos,
“group by” agrupa los términos para cada documento,
y “having” que haya tantos términos en el documento como en la consulta
8.2.3 Modelo de Espacios Vectoriales
8.2.3.1 Introducción
• Propuesto en 1975, hoy el más popular (con variantes)
• También llamado solamente “modelo vectorial”
• Generaliza el modelo booleano al manejar pesos no binarios para los términos de cada documento y de la consulta (query)
• Determina la similitud entre la consulta y cada documento calculando el ángulo entre sus vectores
• La idea principal es que dos documentos son similares si sus vectores apuntan hacia la misma dirección
• Un aspecto importante es la determinación del peso de cada término, típicamente basado en su frecuencia:
- el peso aumenta entre más ocurre en un documento dado
- el peso disminuye entre más aparece en los demás documentos
8.2.3.2 Algoritmo
Uso de frecuencia inversa (TFIDF)
• Considerando
– n = número de términos distintos en una colección
– tfij = número de ocurrencias en el documento i del término tj
– dfj = número de documentos que contienen tj
– idfj = log(d/dfj) = frecuencia inversa de documentos, donde d es el número total de documentos
• entonces cada vector tiene n componentes
• para una gran colección de documentos pequeños, los vectores contendrán muchos ceros
• un cálculo del peso para el j-ésimo elemento del documento di es:
• la similitud entre una consulta Q y un documento Di puede definirse
como el producto de los dos vectores:
En 1988 Salton y Buckley proponen modificaciones a las medidas originales, sugiriendo la siguiente fórmula para el cálculo de pesos del término j en el documento i. Esta variación se debió al argumento de que un match de un término con una frecuencia muy alta puede distorcionar a los demás matches entre el query y el documento.
Similarity Measures
Para medir la similitud entre los vectores formados por el query y cada documento existen muchas formulas, siendo la del coseno la más popular, ya que de una manera simple calcula el ángulo entre ambos vectores.
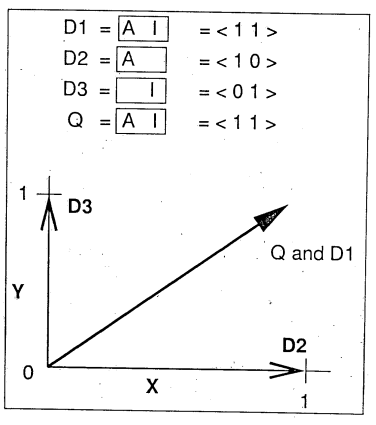






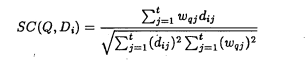
Conceptos Iniciales:
Teoría de Vectores

Tablas posibles para el modelo vectorial
• Docs (IdDoc, NombreDoc, FechaPub, …, texto)
• IndiceInv (IdDoc, Term, tf)
• Terms (term, idf)
• Consulta (term, tf)
• Un pre-proceso puede producir Docs (extrayendo datos de archivos) e
IndiceInv (vía parser, lematización, eliminación de palabras vacías)
• Terms puede producirse mediante:
– insert into terms
select term, log(N/count(*))
from IndiceInv
group by term
• donde N es el número total de documentos y se conoce o se puede obtener previamente (select count(*) from Docs)
• Consulta es solamente una representación tabular de la petición del usuario para facilitar el cálculo del índice de similitud
SQL para espacios vectoriales usando TFIDF
• select i.IdDoc, sum(q.tf * t.idf * i.tf * t.idf)
from consulta q, IndiceInv i, Terms t
where q.term = t.term
and i.term = t.term
group by i.IdDoc
order by 2 desc
• “where” garantiza que se incluyen sólo terminos de la consulta,
“order by”, que se ordenan según el coeficiente de similitud
Cálculo del coseno del ángulo
• Tablas intermedias:
– pesos_docs(IdDoc, peso)
– peso_q(peso)
• Generación de tablas intermedias:
– insert into pesos_docs
select IdDoc, sqrt(sum(i.tf * t.idf * i.tf * t.idf))
from IndiceInv i, Terms t
where i.term = t.term
group by IdDoc
– insert into peso_q
select sqrt(sum(q.tf * t.idf * q.tf * t.idf ))
from consulta q, Terms t
where q.term = t.term
Cálculo del coseno del ángulo
• select i.IdDoc, sum(q.tf * t.idf * i.tf * t.idf) / (dw.peso * qw.peso)
from consulta q, IndiceInv i, terms t,
pesos_docs dw, peso_q qw
where q.term = t.term AND
i.term = t.term AND
i.IdDoc = dw.IdDoc
group by i.IdDoc, dw.peso, qw.peso
order by 2 desc
8.2.3.3 Herramientas
|
Producto |
Lenguaje |
Modelos |
Indexamiento |
API desarrollo |
Licencia |
|
Managing Gigabytes |
C/C++, envoltura Java |
Vectorial |
Propietario |
Ninguno |
Open Source |
|
Xapian |
C/C++ |
Probabilístico |
Propietario |
Limitado |
Open Source |
|
Lucene |
Java |
Vectorial |
Propietario |
Abierto y extendible |
Open Source |
|
MySQL FullText |
C/C++ Java (SMART) |
Vectorial |
Propietario ISAM |
SQL |
Open Source |
|
Egothor |
Java |
Booleano Extendido |
Propietario |
Ninguno |
Open Source |
MySQL Fulltext
|
Creación de tabla y utilización de Match mysql> CREATE TABLE articles ( Mostrar los resultados incluyendo la relevancia de cada uno mysql> SELECT id,MATCH (title,body) AGAINST ('Tutorial') FROM articles;
Ejemplo que recupera los resultados y sus scores de similitud. mysql> SELECT id, body, MATCH (title,body) AGAINST Con la versión 4.0.1 se pueden hacer búsquedas a texto completo incluyendo operadores booleanos. mysql> SELECT * FROM articles WHERE MATCH (title,body)
|
Lucene
Características
- Concurrencia
- Diferentes "ports": Perl, Python, C++, .Net, Ruby
- Scoring
|
|


Diferentes tipos de Fields
|
Field method type
|
Analyzed
|
Indexed
|
Stored
|
Usage
|
| Field.Keyword(String, String) Field.Keyword(String, Date) |
X
|
X
|
Telephone and Social Security numbers, URLs, personal
names Dates |
|
| Field.Unindexed(String,String) |
X
|
Document type (pdf, html, etc), if not used as a search criteria | ||
| Field.Unstored(String, String) |
X
|
X
|
Document titles and content | |
| Field.Text(String, String) |
X
|
X
|
X
|
Document titles and content |
| Field.Text(String, Reader) |
X
|
X
|
Document titles and content |
Core Classes
- IndexWriter: crea el índice y agrega documentos a éste
- Directory: la ubicación del índice, se puede tener un FSDirectory o un RAMDirectory, dependiendo si se desea tener dicho índice en disco o en memoria
- Analyzer: proceso que analiza y limpia el texto (stop words, stemming) antes de que sea indexado
- Document: una colección de Fields
- Field: pareja de un nombre y valor, con que sirven para identificar las distintas partes de un documento; estas parejas pueden ser tan simples como "id" y "234" o bien tan complejas como texto completo "contenido" y "Había una vez...."
- IndexSearcher: abre y emplea el índice en read-only para realizar las búsquedas
- Term: unidad básica de búsqueda (son creados por el indexer)
- Query: distintas subclases para crear queries, BooleanQuery, PhraseQuery, RangeQuery, etc.
- TermQuery: un Term asociado a un query el cual puede poseer un nivel de "boost" para darle mayor peso sobre otros términos
- Hits: contenedor de apuntadores hacia los resultados ranqueados de una búsqueda
Ejemplo de programación con Lucene
23:import org.apache.lucene.analysis.standard.*;
24:import org.apache.lucene.document.*;
25:import org.apache.lucene.search.*;
26:import org.apache.lucene.queryParser.QueryParser;
27:import org.apache.lucene.analysis.Analyzer;
28: 29:import java.io.*;
30:import java.util.*;
31: 32:/** 33: * Class to serve between applications and index files to use retrieval models 34: * with or without Hermes easier 35: * 36: *@author carlos 37: *@created April 16, 2003 38: */ 39:public class JUIRDBC { 40: 41: private String indexfile;
42: private boolean store;
43: 44: 45: 46: /** 47: * Constructor for the JUIRDBC object 48: * 49: *@param indexfile Index file to store/retrieve terms information 50: *@param store true store full documents too, false just store terms 51: */ 52: public JUIRDBC(String indexfile, boolean store) { 53: this.indexfile = indexfile;
54: this.store = store;
55: 56: } 57: 58: 59: /** 60: * Gets from the index file the information requiered for Hermes in the 61: * ExtendedBoolean and Vectorial Models The Document objects returned 62: * contain: resource id of the document containing a term the term itself 63: * tf, term frequency in the document maxtf=1, because we cant determine 64: * this directly idf, inverse frequency of the term related to the 65: * collection* 66: * 67: *@param terms vector containing the query terms 68: *@return vector of mx.udlap.ict.u_dl_a.irserver.dcollections.doctype.Document 69: * objects 70: */ 71: public Vector getFromCollectionTfIdf(Vector terms) { 72: ArrayList vector = new ArrayList();
73: try { 74: IndexReader ireader = IndexReader.open(indexfile);
75: for (int i = 0; i < terms.size(); i++) { 76: TermDocs tdocs = ireader.termDocs(new Term("contents", (String) terms.elementAt(i)));
77: while (tdocs.next()) { 78: mx.udlap.ict.u_dl_a.irserver.dcollections.doctype.Document document =
new mx.udlap.ict.u_dl_a.irserver.dcollections.doctype.Document("" + ireader.document(tdocs.doc()).get("id"), (String) terms.elementAt(i),
"" + tdocs.freq(), "" + 1,
"" + Math.log(ireader.numDocs() / ireader.docFreq(new Term("contents", (String) terms.elementAt(i)))));
79: vector.add(document);
80: 81: } 82: 83: } 84: ireader.close();
85: } catch (Exception e) { 86: e.printStackTrace();
87: } 88: System.out.println("Vector de documentos size= " + vector.size());
89: Collections.sort(vector);
90: return new Vector(vector);
91: } 92: 93: 94: /** 95: * Gets a lucene Document of the specified id, A document contain the some 96: * section, identifies by a name This means that even we chose not to store 97: * the document we will have a result 98: * 99: *@param id Unique identifier of the resource 100: *@return org.apache.lucene.document.Document value, null 101: * if resource doesnt exist 102: *@exception IOException Exception 103: */ 104: public org.apache.lucene.document.Document getResource(String id) throws IOException { 105: IndexReader ireader = IndexReader.open(indexfile);
106: TermDocs tdocs = ireader.termDocs(new Term("id", id));
107: 108: if (tdocs.next()) { 109: return ireader.document(tdocs.doc());
110: } 111: 112: return null;
113: } 114: 115: 116: /** 117: * Gets a list of all the resources(ids) in current index 118: * 119: *@return vector containing ids 120: *@exception IOException Exception 121: */ 122: public Vector getListResources() throws IOException { 123: Vector vector = new Vector();
124: IndexReader r = IndexReader.open(indexfile);
125: 126: int num = r.numDocs();
127: for (int i = 0; i < num; i++) { 128: if (!r.isDeleted(i)) { 129: org.apache.lucene.document.Document d = r.document(i);
130: vector.add(d.get("id"));
131: 132: } 133: } 134: TermEnum te = r.terms();
135: int w = 0;
136: while (te.next()) { 137: w++;
138: } 139: System.out.println(w);
140: r.close();
141: return vector;
142: } 143: 144: 145: /** 146: * Establish connection with a index service Currently just initialize the 147: * file because there is no such service 148: * 149: *@exception IOException Description of Exception 150: */ 151: public void openConnection() throws IOException { 152: if (IndexReader.indexExists(indexfile) == false) { 153: IndexWriter writer = new IndexWriter(indexfile, new StandardAnalyzer(), true);
154: writer.close();
155: } 156: } 157: 158: 159: /** 160: * Termines communication with index service 161: * 162: *@exception IOException Exception 163: */ 164: public void closeConnection() throws IOException { } 165: 166: 167: 168: /** 169: * Adds a resource (or terms of) to the index file 170: * 171: *@param id Unique identifier of the resource 172: *@param file Resource/document to be added 173: *@exception IOException Exception 174: */ 175: public void addResource(String id, File file) throws IOException { 176: 177: IndexWriter writer = new IndexWriter(indexfile, new StandardAnalyzer(), false);
178: writer.addDocument(fileToDocument(id, file));
179: writer.optimize();
180: writer.close();
181: 182: } 183: 184: 185: /** 186: * Removes a resource (and/or its terms) from the index file 187: * 188: *@param id id of document to be deleted 189: *@exception IOException Exception 190: */ 191: public void deleteResource(String id) throws IOException { 192: IndexReader ireader = IndexReader.open(indexfile);
193: TermDocs tdocs = ireader.termDocs(new Term("id", id));
194: 195: if (tdocs.next()) { 196: ireader.delete(tdocs.doc());
197: } 198: 199: ireader.close();
200: 201: } 202: 203: 204: /** 205: * Search a query with lucene 206: * 207: *@param line string of terms to be searched 208: *@return lucene hits 209: *@exception Exception Exception 210: */ 211: public Hits search(String line) throws Exception { 212: Searcher searcher = new IndexSearcher(indexfile);
213: Analyzer analyzer = new StandardAnalyzer();
214: 215: Query query = QueryParser.parse(line, "contents", analyzer);
216: System.out.println("Searching for: " + query.toString());
217: 218: return searcher.search(query);
219: } 220: 221: /** 222: * Search a query with lucene specifying the file to search 223: * just to show the PhraseQuery feature 224: * 225: *@param line string of terms to be searched 226: *@return lucene hits 227: *@exception Exception Exception 228: */ 229: public Hits search(String filename, String line) throws Exception { 230: Searcher searcher = new IndexSearcher(indexfile);
231: Analyzer analyzer = new StandardAnalyzer();
232: 233: Query query = QueryParser.parse(line, "contents", analyzer);
234: PhraseQuery phrasequery=new PhraseQuery();
235: phrasequery.add(new Term("path",filename));
236: BooleanQuery bquery=new BooleanQuery();
237: bquery.add(query,true,false);
238: bquery.add(phrasequery,true,false);
239: System.out.println("Searching for: " + bquery.toString());
240: 241: return searcher.search(bquery);
242: } 243: 244: 245: /** 246: * Converts a file to Lucene's specification of Document The document 247: * contains two fields: id - the document id contents - file content 248: * 249: *@param id identifier of current document 250: *@param f file to be added 251: *@return Document Value 252: *@exception java.io.FileNotFoundException Exception 253: */ 254: private org.apache.lucene.document.Document fileToDocument(String id, File f)
255: throws java.io.FileNotFoundException { 256: 257: // make a new, empty document 258: org.apache.lucene.document.Document doc = new org.apache.lucene.document.Document();
259: 260: doc.add(Field.Keyword("id", id));
261: // Add the path of the file as a field named "path". Use a Text field, so 262: // that the index stores the path, and so that the path is searchable 263: doc.add(Field.Keyword("path", f.getName()));
264: 265: // Add the last modified date of the file a field named "modified". Use a 266: // Keyword field, so that it's searchable, but so that no attempt is made 267: // to tokenize the field into words. 268: doc.add(Field.Keyword("modified",
269: DateField.timeToString(f.lastModified())));
270: 271: // Add the contents of the file a field named "contents". Use a Text 272: // field, specifying a Reader, so that the text of the file is tokenized. 273: // ?? why doesn't FileReader work here ?? 274: FileInputStream is = new FileInputStream(f);
275: Reader reader = new BufferedReader(new InputStreamReader(is));
276: try { 277: char[] documento = new char[new Long(f.length()).intValue()];
278: FileReader freader = new FileReader(f);
279: freader.read(documento, 0, new Long(f.length()).intValue());
280: if (store) { 281: doc.add(Field.Text("contents", new String(documento)));
282: } else { 283: doc.add(Field.Text("contents", reader));
284: } 285: 286: } catch (Exception e) { 287: } 288: // return the document 289: return doc;
290: } 291: 292: 293: public static void main(String args[])
294: { 295: if(args.length<1)
296: { 297: System.err.println("Falta incluir la busqueda entre comillas, ej \"xml arbol xsl fo\"");
298: return;
299: } 300:
301: try 302: { 303: File dir=new File("lucene.idx");
304: if(dir.exists())
305: { 306: File files[]=dir.listFiles();
307: for(int j=0;j<files.length;j++)
308: files[j].delete();
309: } 310: 311: JUIRDBC lucene=new JUIRDBC("lucene.idx",true);
312: lucene.openConnection();
313: lucene.addResource("syllabus",new File("/home/digital/html/ict-pr2005/is346/syllabus.html"));
314: lucene.addResource("01",new File("/home/digital/html/ict-pr2005/is346/admon01.html"));
315: lucene.addResource("02",new File("/home/digital/html/ict-pr2005/is346/admon02.html"));
316: lucene.addResource("03",new File("/home/digital/html/ict-pr2005/is346/admon03.html"));
317: lucene.addResource("04",new File("/home/digital/html/ict-pr2005/is346/admon04.html"));
318: lucene.addResource("05",new File("/home/digital/html/ict-pr2005/is346/admon05.html"));
319: lucene.addResource("05_hibernate",new File("/home/digital/html/ict-pr2005/is346/admon05_hibernate.html"));
320: lucene.addResource("05_ejb",new File("/home/digital/html/ict-pr2005/is346/admon05_ejb.html"));
321: lucene.addResource("05_ldap",new File("/home/digital/html/ict-pr2005/is346/admon05_ldap.html"));
322: lucene.addResource("06",new File("/home/digital/html/ict-pr2005/is346/admon06.html"));
323: lucene.addResource("07",new File("/home/digital/html/ict-pr2005/is346/admon07.html"));
324: lucene.addResource("08",new File("/home/digital/html/ict-pr2005/is346/admon08.html"));
325: lucene.addResource("09",new File("/home/digital/html/ict-pr2005/is346/admon09.html"));
326: lucene.addResource("10",new File("/home/digital/html/ict-pr2005/is346/admon10.html"));
327: lucene.addResource("11",new File("/home/digital/html/ict-pr2005/is346/admon11.html"));
328:
329: if(args.length=1)
330: Hits hits=lucene.search(args[0],args[1]);
331: for(int i=0;i<hits.length();i++)
332: { 333: Document doc=hits.doc(i);
334: System.out.println(hits.score(i)+" "+hits.id(i)+" "+doc.getField("id")+" "+doc.getField("path"));
335:
336: } 337: lucene.closeConnection();
338: 339: }catch(Exception e)
340: { e.printStackTrace(); } 341: 342: } 343: 344: 345:}
Uso de vectores para encontrar similitudes con Lucene (fragmento cap.5 Lucene in Action)8.2.5 Modelo Booleano Extendido
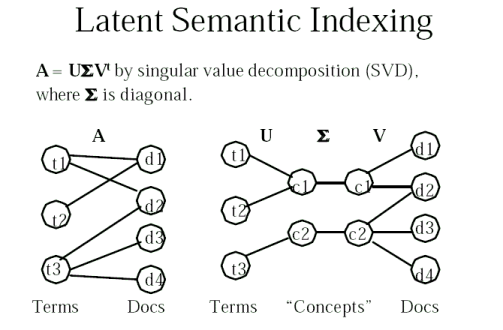
8.2.5 Modelo LSI (Latent Semantic Indexing)
La meta es calcular la similitud query-documento haciendo matching entre conteptos en vez de términos
La manipulación de matrices es empleada para identificar los "key concepts"
Singular value decomposition (SVD) es usada para reordenar el espacio de términos-documentos para reflejar los patrones asociacitivos más importantes e ignorar las pequeñas y menos importantes diferencias (Deerwester, JASIS, 1990).
Calcular la matriz, X
- Calcular la SVD de X
- Lo anterior resultará en 3 matrices
- X = T S D
- S, contiene |D| singular values donde |D| es el número de documentos
- Escoger los k más representativos para formar S'. Esta es la parte interesante ya que escogiendo todo |D| resultaría en la matriz original, mientras que escoger valores menores resultará en un "fuzzier matrix".
- Eliminar las columnas correspondientes de T y D para formar T' y D'.
- Ahora calcular X' = T' S' D'?
Empleando la nueva X'
- Comparar 2 términos
- Tomar el producto punto de 2 vectores (renglón) de X'
- Comparar 2 documentos
- Tomar el producto punto de 2 vectores (columna) de X'
- Comparando un query con un documento
- Se necesita hacer que el query parezca otro documento, esto se puede hacer mapeando el queru en un espacio bidimensional: (qT)(T')(S')-1
Las operaciones de SVD pueden hacerse con paquetes matriciales como JAMA o el package javax.vecmath
8.3 Estrategias para mejorar RI
• Se han propuesto mecanismos que mejoran la recuperación de los modelos “clásicos”
• Funcionan agregando o eliminando términos de la consulta original o limitando el espacio de búsqueda
• Cada estrategia puede operar con distintos modelos (como “utilerías”) y su desempeño es altamente variable dependiendo de la naturaleza de la colección (heurísticas)
Algunas estrategias:
• Retroalimentación de relevancia
– Los t términos más pesados de los n documentos más relevantes se agregan a la consulta original para formar una nueva consulta
• Pre-clasificación (clustering)
– La colección se organiza en grupos y la consulta se compara solamente con los grupos que se consideran relevantes
• Recuperación en pasajes
– La consulta se aplica solo a porciones (pasajes) de los documentos que se consideran lo más relevante
• Identificación de frases (parsing)
– Se aplican reglas o listas de frases conocidas que se tratan como términos (“New York”, “Ciudad Juárez”, etc.)
• N-gramas
– La consulta se divide en secuencias de caracteres y se usan en lugar de los términos originales—resistentes a errores de OCR e independientes del idioma
• Tesauros
– Se usan términos relacionados para búsquedas semánticas
• Redes semánticas
– Se generan jerarquías de conceptos para enriquecer los términos de búsqueda
• Análisis de regresión
– Se usan técnicas estadísticas para identificar las variables (parámetros) que hacen que un documento sea relevante y luego se usan para buscar otros documentos relevantes
8.4 Aplicaciones "ready to use"
- SWISH-E, SWISH++
http://swish-e.org- Glimpse and Webglimpse
http://webglimpse.net- Namazu
http://www.namazu.org- ht://Dig
http://htdig.sourceforge.net/- Harvest y Harvest-NG
http://www.sourceforge.net/projects/harvest
http://webharvest.sourceforge.net/ng- Microsoft Index Server
http://www.microsoft.com/NTServer/techresources/webserv/IndxServ.asp- Verity
http://www.verity.com